S3 Bucket Protection for Disaster Recovery
Multiple storage architectures exists, one of them is Object storage., Object Storage aka Object-based storage that manages the data as objects, unlikely to the other architectures like File ( which manages as file hierarchy ) and Block ( which manages blocks in sector and tracks )
Many startups and enterprises used object storage for their massive amount of unstructured data. Facebook is using Object storage for storing photos, Spotify uses it for songs, some banks use for storing the KYC data, on-prem datacenter store the long-tern archival data in the object storage.
Amazon Simple Storage Service S3 is one of the well-known services offered by AWS, S3 is on the object storage architecture. and Amazon guarantees the “four nines” service availability ( 99.99%) and “eleven nines” for the data in the S3 storage. means the S3 can go down / unavailable for a maximum of 52.56 minutes per year and you go likely a hundred years without a loss of a single file out of a billion but this is not always the case.
You can read some of my previous posts to understand why we need backup and DR strategy for your business in the cloud.
In order to prevent any unexpected downtime for your business-critical applications which use the S3 for storing the data, you can use an Amazon S3 feature called Cross-Region Replication.
Replication is not a backup
If your data is corrupted, the same data will be replicated to the other end of the storage
S3 Replication
S3 Replication is the feature that enables an automatic and async copy of your data from one bucket to another bucket
Copies of replicated objects in the destination bucket are identical to those in the source bucket, which means that these objects have the same name and metadata.
You will have the option to choose all the objects to replicate or have filtered by prefix or object with tags, and you have option to enable the replication for existing objects or only for the new objects
And you will have option to enable the encryption ( data at rest) using the AWS default KMS or CMK. and the object which the role associated has permission to read and read ACL will only be replicated.
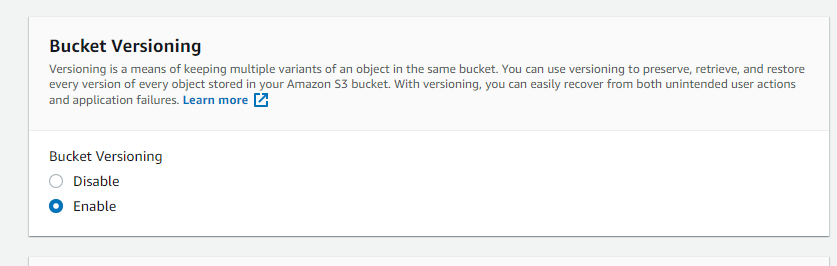
AWS Replication objects are not “transitive” you cannot have multi-level replication which is replicated the object to 3rd bucket from the second bucket is not possible. and you must enable bucket versioning to enable the replication
Setup S3 Replication in AWS Console
I have two buckets namely asvignesh-src and asvignesh-dst where the src is in US-EAST-1 and the target is US-EAST-2

Go to Management of the Source Bucket and click on “Create replication rule”
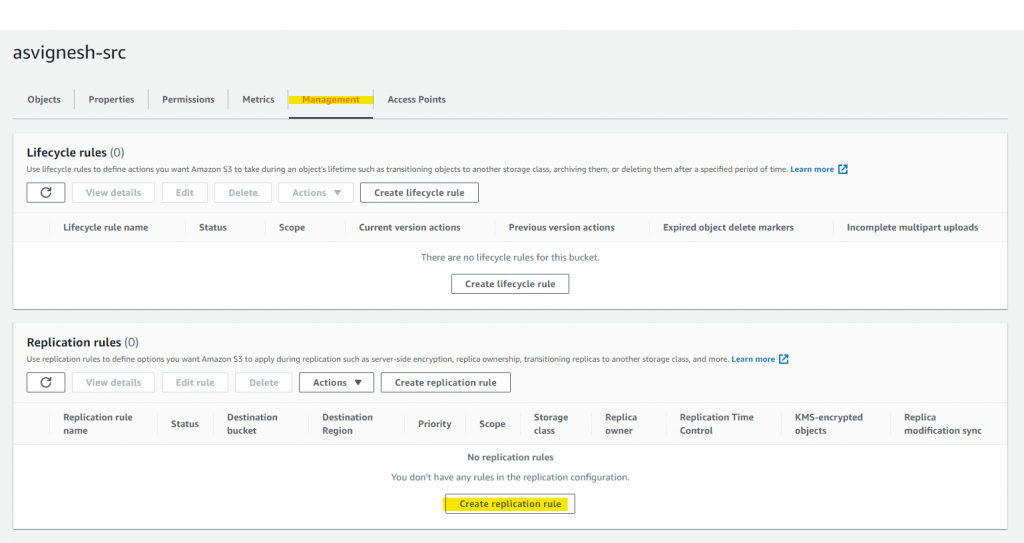
Create Replication Rule
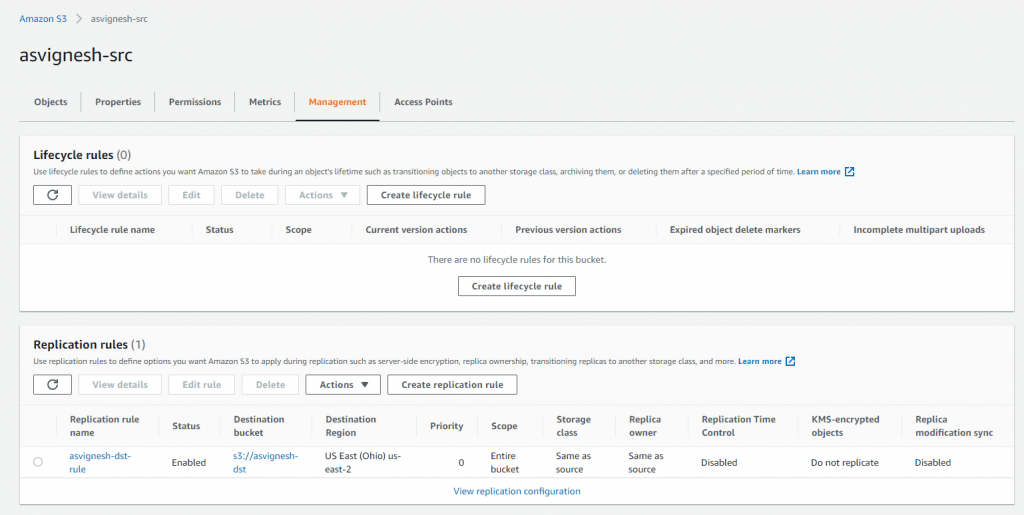
Set the replication rule name and status enable
Configure the rule scope for the replication
Choose the destination bucket, you will have the option to choose the bucket in a different account, make sure you have permission for the bucket
Choose the IAM Role for the S3 Replication ( sample role )
you can choose the encryption ( you can use existing CMK or create new key for replication object or go with default KMS )
You have a option to choose the destination storage class, you can choose to have reduced-redundancy to save some bucks
Additional replication Options like ETC, metric and notification, replica modification sync and delete marker.
Delete marker is when you delete the object the S3 mark the object as deleted in the version, you have the option to delete the delete marker which will make the file available again
Testing the Replication Feature
I uploaded a file asvignesh.log to the src bucket
it took some time to see the file in the target bucket
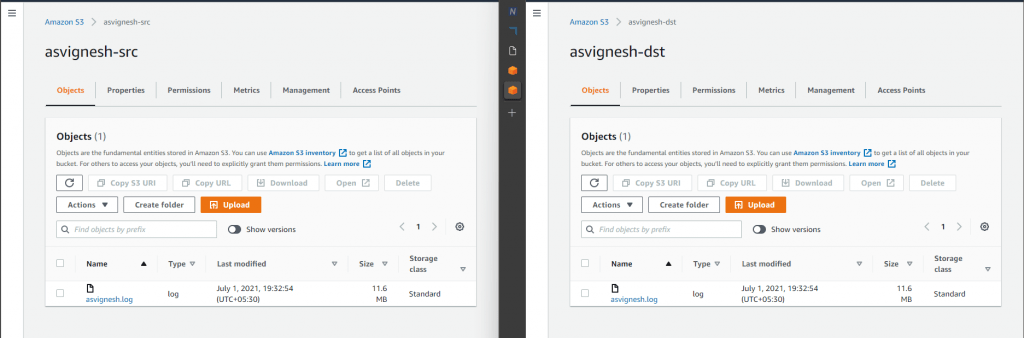
If you like to sync the files more aggressively, you can enable the RTC Replication Time Control which enables 99.99% of objects in the bucket will be replicated to the target bucket within 15 minutes and provides the replication metrics and notifications with additional cost
Note : Apart from the storage cost you are billed for the data transfer charges as well for using this feature.
Create Replication Rule using Java SDK
Create the S3Client Object
AmazonS3 s3Client = AmazonS3Client.builder()
.withCredentials(new ProfileCredentialsProvider())
.withRegion(clientRegion)
.build();Create a target bucket
CreateBucketRequest request = new CreateBucketRequest("asvignesh-dst", region.getName());
s3Client.createBucket(request);
Enable Versioning
BucketVersioningConfiguration configuration = new BucketVersioningConfiguration().withStatus(BucketVersioningConfiguration.ENABLED);
SetBucketVersioningConfigurationRequest enableVersioningRequest = new SetBucketVersioningConfigurationRequest("asvignesh-dst", configuration);
s3Client.setBucketVersioningConfiguration(enableVersioningRequest);Create Replication Rule
new ReplicationRule()
.withPriority(0)
.withStatus(ReplicationRuleStatus.Enabled)
.withDeleteMarkerReplication(new DeleteMarkerReplication().withStatus(DeleteMarkerReplicationStatus.DISABLED))
.withFilter(new ReplicationFilter().withPredicate(new ReplicationPrefixPredicate(prefix)))
.withDestinationConfig(new ReplicationDestinationConfig()
.withBucketARN(destinationBucketARN)
.withStorageClass(StorageClass.Standard)));Set bucket replication
s3Client.setBucketReplicationConfiguration("asvignesh-src",
new BucketReplicationConfiguration()
.withRoleARN(roleARN)
.withRules(replicationRules));Disclaimer: The scripts/code in this post are given as-is without any warranties. Please consider them as guidelines. Please don’t use them in your production environment until thoroughly testing them and making sure the processes work correctly.
Also published on Medium.